
ACL 2019 Thoughts and Notes
16 Aug 2019ACL 2019, held in Florence, Italy, was the largest ACL to date. The event was spread out over 8 halls, with simultaneous talks (up to 6 simultaneous tracks) and a poster session in every slot. ACL was also co-located with several (almost too many) excellent workshops, each of which could warrant several days of attendance in their own right. Unfortunately, as it typically goes with these things, we couldn’t take in everything. Regardless, in this post, we’ll attempt to condense the conference into a quick description of interesting posters and talks that we (Vinit and Daniel) did have the chance to see.

ACL: Day 1
The conference kicked off on a Monday (after a tutorial-filled Sunday) and was plagued with delayed and cancelled flights. Flustered-looking attendees arrived throughout the day, lugging massive suitcases into the venue so as to not waste any more conference time. Unfortunately, we were both also unlucky with travel and missed a good portion of the first day.
Multi-Task Semantic Dependency Parsing with Policy Gradient for Learning Easy-First Strategies
This paper is another success story for reinforcement learning in NLP. As more and more people try to employ RL techniques (e.g. policy gradient) for NLP tasks, they often realize that getting good results is not as easy as it seems (for an example, see this paper). But for semantic dependency parsing, giving the parser a very free hand in choosing attachment order and learning it with RL seems to work quite well and lead to an easy-first strategy.
Don’t Take the Premise for Granted
Following a lot of recent work which presented findings showing that NLP models can leverage statistical biases and dataset artifacts to perform well on different datasets without really learning the intended tasks, this paper presents an approach to tackling this problem for Natural Language Inference (NLI). By making the models predict the probability of a premise given the hypothesis and entailment label, they show that they can better capture the relationship between the premise and hypothesis. This is demonstrated with better transfer of performance between datasets and less reliance on some well-known biases. The paper presents an interesting solution and perhaps calls for a similar treatment of other tasks.
ACL: Day 2
The keynote by Liang Huang on Simultaneous Interpretation was rather inspiring, showing that a very simple idea (prefix-to-prefix training for MT) can be very effective in allowing a system to learn predictive translation automatically. This seems like something many groups have been working on recently, and Baidu demonstrated its success by deploying such a system. Too bad for the 3000 worldwide certified simultaneous interpreters’ jobs…
We Need to Talk About Standard Splits
This paper is a very welcome critique of the accepted wisdom of standard splits, i.e. the principle of consistently using the same training/validation/test split to evaluate different systems. Their critique suggests that the use of a single standard split may result in Type I errors, which may be misleading in the context of a system being truly “state-of-the-art”. The solution? Use randomly-generated splits with Bonferroni-corrected hypothesis testing.
Is Attention Interpretable?
In a very comprehensive work on a theme that’s been growing in popularity, Serrano et. al assess the value of self-attention as a tool for visualising importance. They do so by measuring when output decision flips occur based on the blanking-out of “more attentive” words, concluding that attention isn’t as interpretable as we’d assumed it was. An upcoming EMNLP paper presents some counter-arguments.
Correlating Neural and Symbolic Representations of language
Representational similarity analysis (RSA) was a recurring topic during this ACL. In this work, Chrupala & Alishahi extend traditional RSA – which relies on comparing representations from discrete media – to what they call RSA_regress, where the predictability of one representation from the other is analysed. Using this method, they are able to capture correlations between different representational spaces (i.e. sentence embeddings), demonstrating to what extent a particular representation encodes linguistic information (constituency trees in this case).
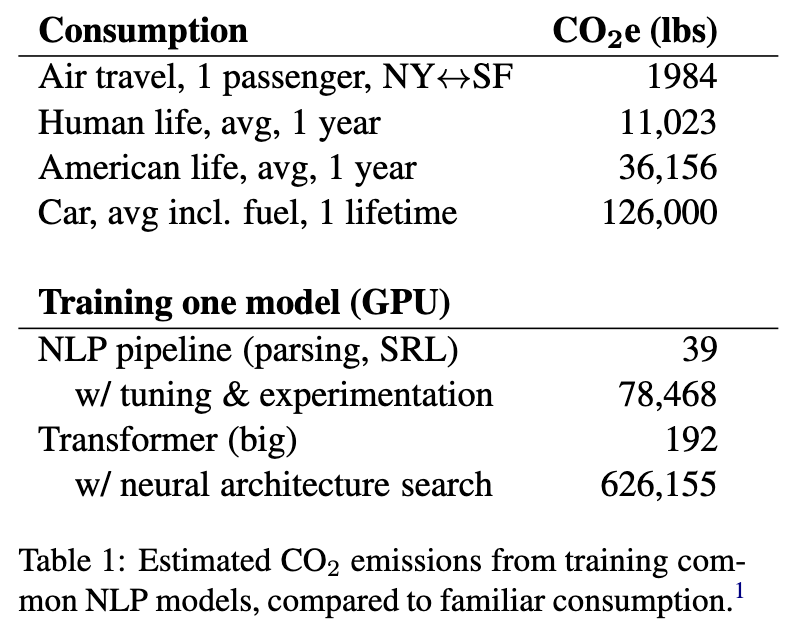
Energy and Policy Considerations for Deep Learning in NLP
A paper that’s made NLP collectively take a long, hard look at itself is Strubell et al.’s energy and policy considerations, which describes exactly how much CO2 we’ve been emitting when we train our models. The numbers, when you add them all up, are quite alarming, and bear some thought: can all our experiments be worthwhile?
On the Distribution of Deep Clausal Embeddings
Thematically different than many papers this ACL, this work presents an analysis of large, automatically annotated corpora to verify phenomena discussed in theoretical linguistics. Specifically, the authors focus on whether there are hard constraints on the depth of clausal embeddings within sentences. Ultimately, they discover that, while deeply embedded clauses tend to be shorter, there’s no actual hard constraints on embedding depth. For more linguistically-minded folks, this work is a testament to how NLP and ever-increasing computing power can aid in answering fundamental questions in the field.
Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference
This paper is a nice and clear demonstration that current NLI test sets are not testing what we think they are testing. Together with the aforementioned standard splits paper and many other papers on artifacts and evaluation, the community is (seemingly) arriving at a consensus: we need to be a lot more rigorous about test sets — not just hope that sampling from the general distribution will teach us something useful. Even if most problems in life are easy to solve, it doesn’t mean we should overfit to them and ignore the few hard cases!
ACL: Day 3
Bridging the Gap between Training and Inference for Neural Machine Translation
The idea behind this paper (the best long paper at ACL) is as ingenious as it is simple - NMT systems are conventionally trained with ground truth previous words during decoding. This is obviously not replicable at test time, and the authors propose methods to bridge this gap by sampling from the predicted (“oracle”) distribution. They propose methods that sample from world-level distributions and compare these with a method of sampling complete sentences - using beam search, and BLEU as a metric - and using the words from the entire sampled sentence as context.
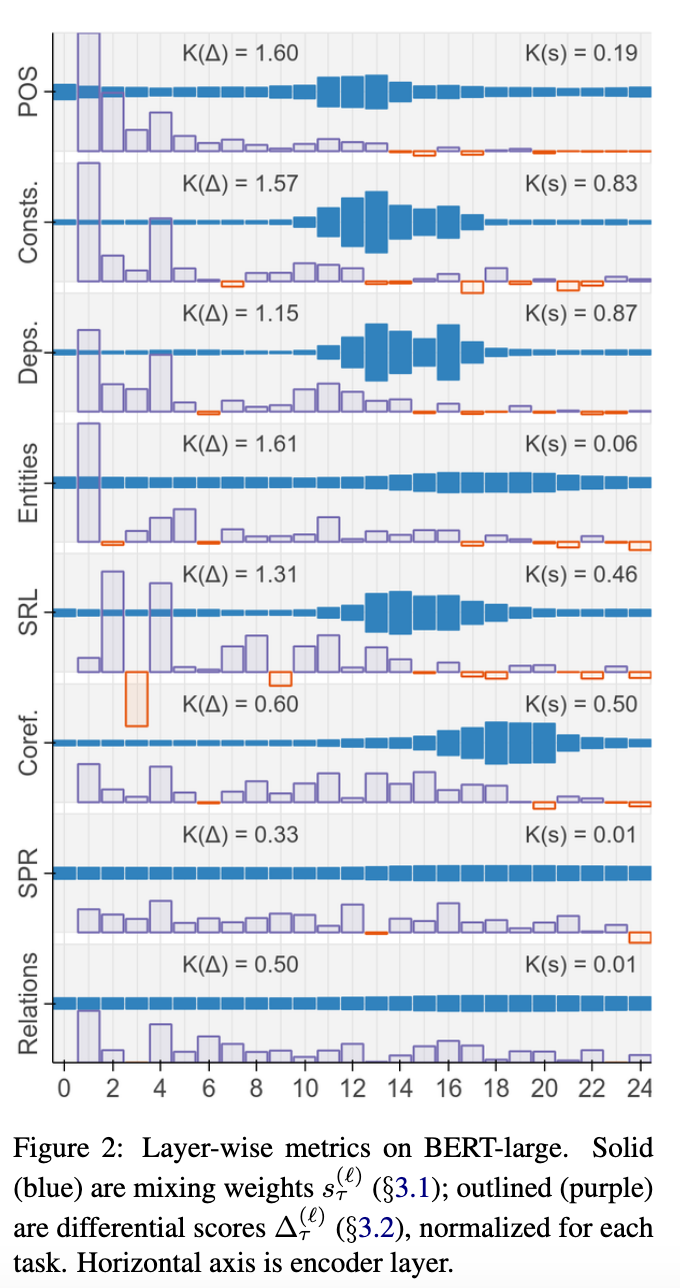
BERT rediscovers the classical NLP pipeline
This paper had been picking up some buzz on Twitter before ACL. It’s a great addition to the recent theme of probing pretrained sentence encoders. The authors tack diagnostic classifiers onto scalar mixes of BERT layers and attempt to recover various levels of linguistic annotation. In doing so, they discover that, layer-by-layer, BERT tends to resemble the classic NLP pipeline, with lower layers likelier to contribute to POS-tagging, whilst higher layers contribute more to structured, “complex” tasks like NER.
A surprisingly robust trick for the Winograd Schema Challenge
The authors of this work describe how the Winograd schema challenge - a corpus with “commonsense reasoning” based pronominal disambiguation tasks - can be made a lot easier by fine-tuning on other pronoun resolution datasets. This is surprising, to quote the authors, “because previous work (Opitz and Frank, 2018) implies that generalizing to WSC273 is hard.” Using this trick to fine-tune BERT, they report 8.8% and 9.6% improvement over state-of-the-art on the WSC273 and WNLI datasets.
What kind of language is hard to language-model?
The paper asks what turns out to be quite an elusive question. When trying to design better language models we come across different challenges in different languages, but how do you measure language modeling difficulty objectively? A follow up on last year’s Are All Languages Equally Hard to Language-Model?, here the authors expand their experiments to non-Indo-European languages. Carefully controlling for superficial factors and biases in the data, they find that, contrary to previous results, linguistic factors have no strong correlation with LM difficulty, but vocabulary size and sentence length do.
How multilingual is multilingual BERT?
An extension of the BERTology theme into a multilingual domain. The authors use task-specific annotations in one language to fine-tune BERT, and evaluate the fine-tuned model on different languages. The trained models do work after transfer, even on languages with completely different scripts (and therefore zero lexical overlap), indicating that multilingual BERT is, surprisingly, pretty multilingual.
Analyzing multi-headed self-attention
The transformer is, in general, widely seen as a fundamental building block for NLP — particularly for tasks like machine translation. Multi-headed self-attention (MHSA) is a critical component of the transformer architecture. In Analyzing MHSA, the authors evaluate per-head contribution, and discover that the “most confident” heads are often the most consistent and interpretable (from a linguistic sense). This leads to the question: how many of an encoder’s total heads are, conversely, redundant? Turns out, ‘pruning’ approximately 80% of an encoder’s heads trained on the En-Ru WMT dataset leads to a drop of only 0.15 BLUE.
Towards Complex Text-to-SQL in Cross-Domain Database with Intermediate Representation
Here, the authors tackle a tough issue in semantic parsing: namely, that SQL sucks. By converting it to a friendlier representation for parsers, they show a significant improvement on the recent Spider dataset, which seems to be orthogonal to other recent contributions such as Representing Schema Structure with Graph Neural Networks for Text-to-SQL Parsing.
Compositional Semantic Parsing across Graphbanks
A nice demonstration that you can learn a general semantic parser that’s better on many representations, rather than focusing on one and treating the others as “auxiliary” (as done previously in Multitask Parsing Across Semantic Representations). This is an attractive teaser for the CoNLL 2019 shared task on Cross-Framework Meaning Representation Parsing.
BlackboxNLP 2019
After 2018’s stellar reception, BlackboxNLP was renewed for its second chapter this year. Here are some papers/presentations we managed to catch.
Transcoding Compositionally
In transcoding compositionality, the authors present seq2attn, an architecture designed to discover compositionality. The two main innovations here are 1.) expressing the attention as a weighted sum of non-contextual embeddings rather than of contextualised vector, and 2.) using a learned initialisation vector for the decoder, instead of the encoder’s last state — this encourages the decoder to examine “disentangled” representations of the input. The authors evaluate their approach on two composition-oriented datasets, and also test the ability of seq2attn to overgeneralise given non-compositional examples.
Blackbox Meets Blackbox
In another RSA-themed paper, the authors propose an extension to RSA that they dub “ReStA” - representational stability analysis. The motivation is to compare, instead of two separate encoders, the same encoder, given a change in one particular parameter. The authors perform two sets of experiments: in the first, they compare encoders to each other, varying the length of prior context (the task being modelling a Harry Potter corpus); in the second, they use RSA to compare the encoders to fMRI data obtained from participants reading the same text. Their observations show strong differences between language models for the first part, and that (amongst other observations) LSTM based models tend to be more similar to fMRI readouts.
Sentiment analysis is not solved!
The authors annotate and release a pretty helpful set of English sentences, from six datasets, that three state-of-the-art sentiment classifiers. They then perform a fine-grained annotation of the types of errors, providing insight into the more pervasive issues sentiment classifiers have. Some of these issues (like negation or modality) have already been studied, but they show that modern neural methods still tend to fail when presented with these phenomena.
Character Eyes
This work attempts to “see language through character-level taggers”: the authors introduce a metric called the POS-discrimination index, which is higher for a hidden unit if it acts as a better discriminator for POS tagging. They observe imbalances across forward and backward activations, particularly for agglutinative languages, where the taggers tend to prefer the more imbalanced models. They also show that prefixing languages tend to be more imbalanced in favour of backward units, with the opposite true for suffixing languages, suggesting that “LSTMs are better at detecting formations towards their final state”.
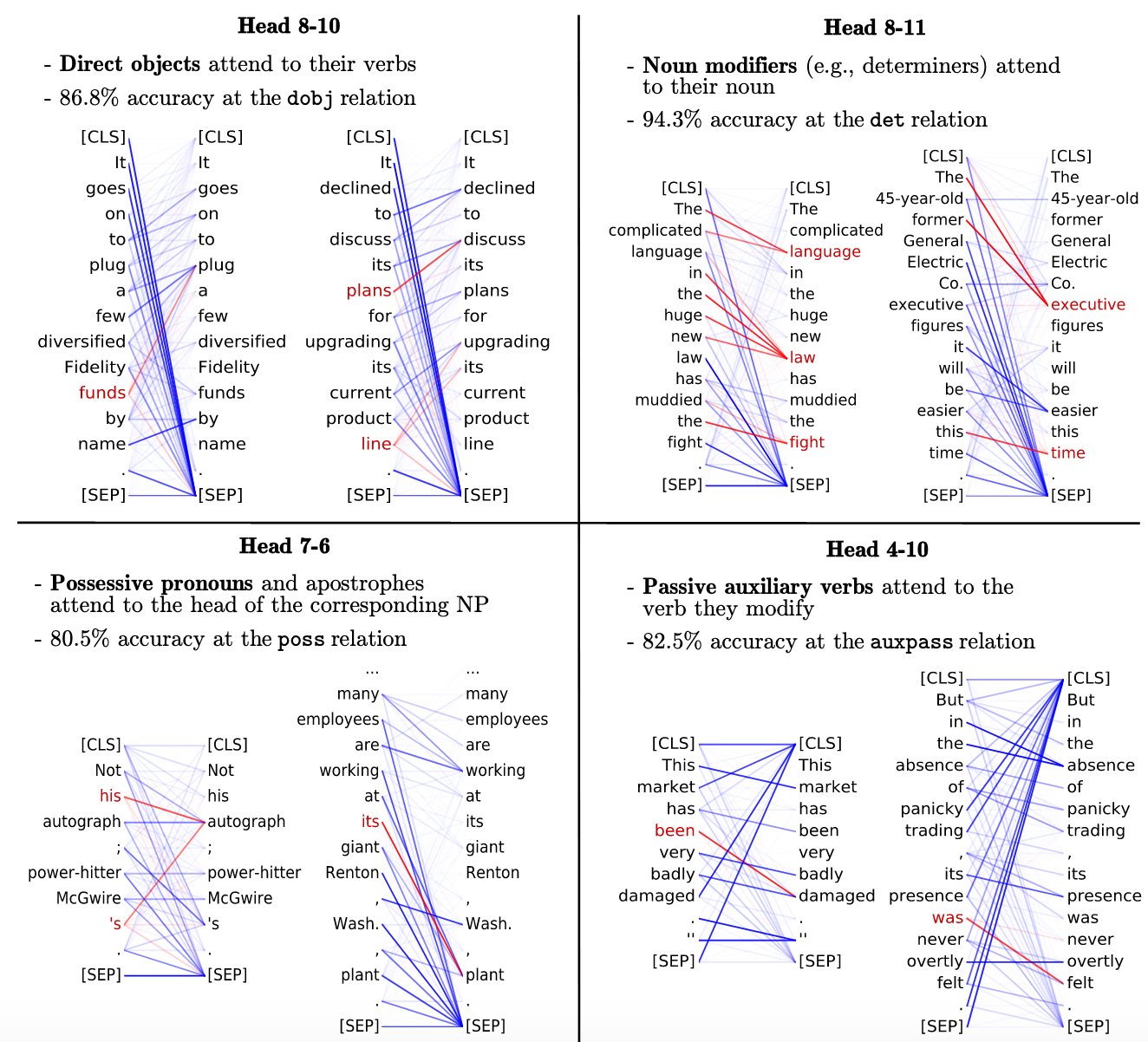
What Does BERT Look At?
And finally, the winner of the best paper award at the workshop - this paper is an analysis, not of BERT’s hidden representations, like most other probing work, but of its attention heads. The authors extract valuable linguistic insight, including some surprising results, such as the fact that heads within the same layer have similar attention distributions.
Trends
1. BERTology
- What Does BERT Look At?
- How multilingual is multilingual BERT?
- BERT rediscovers the classical NLP pipeline
2. Representational Similarity Analysis
3. Attention to Attention
4. Are we doing it right?
- We Need to Talk About Standard Splits
- Energy and Policy Considerations for Deep Learning in NLP
- Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference