
On sentence representations: what can you fit into a single #$!%@*&% blog post?
26 Nov 2018From 2013 onward, word embeddings have largely dominated the conversation regarding the representation of language in vector form. However, though they help us gain insight into language at the lexical level (i.e. meaning as a function of distribution), their primary utility is usually intermediary. In other words, we often employ word embeddings as piecewise input to another subsystem – such as recurrent or convolutional networks, or transformers – which then attempt to make sense of words as constituent parts composing higher-order units of language, usually sentences. The representation yielded by this latter approach can be imagined as a sentence encoding/embedding/vector in its own right, learned with a specific task objective in mind (text classification, POS-tagging, natural language inference, etc.). However, while word embeddings themselves have often come pre-trained and been assumed to generalize well across the vast majority of NLP tasks, such sentence-level representations have traditionally been specialized for a single task. This lead to the the question: can we go beyond word embeddings and represent sentences in a way that is both principled and generalizable across a wide array of tasks?
I. A problem of compositionality?
The problem of extending vector-based word representations to longer pieces of text (such as phrases, sentences, paragraphs, etc.) has long been an active area of research. At the crux of the issue lies the fundamental idea of compositionality in vector space models. This is can be loosely described as the ability to compose discrete parts (e.g. words) into larger units (e.g. sentences), as well as to analyze the latter as combinations of the former. This is, in itself, a fascinating topic of research which goes beyond NLP and machine learning and indeed has a rich history in physics and in social and cognitive sciences (see here).
Within NLP, research into computational methods for compositionality kicked off once it became clear that word-based vector space models could be constructed (see Schütze, H. (1993) and Bengio et al. (2003)). Such models were theoretically capable of orienting words along latent syntactic and semantic axes in a high-dimensional space, thereby enabling inference via simple linear algebraic means (e.g. cosine distance between word vectors). One canonical method of building such word vector space models involved computing a matrix of co-occurrence for all words in a corpus and applying a form of dimensionality reduction on it - usually via some sort of matrix factorization technique (see Schütze, H. (1998) or GloVe). With the advent of dense word embeddings, it became evident that word-based vector spaces could also possess inherent compositional qualities in and of themselves. Not that it ever needs further citation, but recall the now-ubiquitous analogy: “man is to king as woman is to X”. With a good model, it is possible to correctly solve for X by means of simple vector arithmetic, thereby confirming some degree of compositionality.
However, just because two vectors can be added (or averaged, or max-pooled) to represent some aspect of their compositional meaning, it does not necessarily follow that the same principle can be extended to form sentences or phrases. This should seem intuitive - even though the two sentences “my dog devoured the leftovers” and “the leftovers devoured my dog” would share the same vector when all constituent word embeddings are added, it is clear that the latter sentence makes little sense in modern English and should be clearly distinguished from the former. Intuitively, factors like word order and underlying sentence structure should be crucial for creating meaningful sentence representations. Finding principled methods that take such information into account is the fundamental challenge in sentence representation. In the next section, we will briefly review the history of sentence representation and provide some context for how this problem has evolved throughout the years.
II. History
Mitchell and Lapata (2008) is among the first works to directly address the issue of semantic compositionality in vector-based models of language. They experiment with a number of additive and multiplicative methods of composition, evaluating them via a sentence similarity rating experiment. The results are intuitive: additive bag-of-word models are outperformed by weighted addition models, which allow weighing of the contribution of different sentence constituents (thereby increasing the ‘syntax-awareness’ of the models). Models with a multiplicative component prove to be even better, facilitating interactions between constituents and resulting in vectors that are sparser and less noisy.
Taking inspiration from formal semantics, Baroni and Zamparelli (2010) propose a model where nouns are represented as vectors and adjectives are linear maps (functions). The latter take the former as input and produce vectors as output. In a similar vein, Coecke et al. (2010) present a comprehensive mathematical framework for unifying distributional vector-space models with a compositional theory for grammatical types, which relies on the algebra of Pregroups. This framework (DisCoCat) computes the meaning of a (grammatical) sentence from the meanings of its constituents.
Grefenstette and Sadrzadeh (2011), Greffenstette et al. (2014), and Greffenstette (2013) offer an empirical evaluation DisCoCat-based models. Their implementation involves learning matrices for words with relational types (adjectives, verbs) and vectors for words with atomic types (nouns) from a corpus, then applying the former to the latter in order to compute the meaning of a sentence. In two disambiguation tasks (transitive vs. intransitive verbs), these models demonstrate an advantage over their competition in experiments involving higher syntactic complexity (transitive verbs).
Socher et al. (2012) and Socher et al. (2013) propose a compositional architecture that assigns a vector and a matrix to every word in the parse tree of a given sentence. The vector is meant to capture the inherent meaning of the constituent, while the matrix captures how it interacts with its neighbors. Given the parse of a sentence in the form of a binary tree (or greedily inferring it), this model - called a Matrix-vector recursive neural network (MV-RecNN) - computes the semantic representation \(( \vec{c} , C )\) of each non-terminal node in the tree by performing the following two operations on its children \(( \vec{a} , A )\) and \(( \vec{b} , B )\), where \(W\) and \(W_m\) are projection matrices which are also to be learned:
\[\begin{align*} \vec{c} = W \times \begin{bmatrix} B \times \vec{a} \\ A \times \vec{b} \end{bmatrix} \end{align*}\] \[\begin{align*} C = W_m \times \begin{bmatrix} A \\ B \end{bmatrix} \end{align*}\]Assigning vector-matrix representations to all words instead of words only belonging to a single part of speech category allows for greater flexibility, which leads to good performance on a variety of evaluation and downstream tasks reported by the authors. Socher et al. (2014) present an interesting variant of this model - DT MV-RecNN - which utilizes a dependency tree rather than a constituency tree, as was used in the original.
Blacoe and Lapata (2012) offer an evaluation of the aforementioned additive, multiplicative, and recursive neural network-based methods on phrase similarity and paraphrase detection tasks. Surprisingly, the authors find that the simple linear algebraic methods (which do no take word order into account) perform on par with - or outperform - the recursive neural network model on the phrase similarity task and are only slightly outperformed on the paraphrase detection task.
intermezzo
In Phrase similarity in humans and machines, Gershman and Tenenbaum presented an important critique of compositional semantic models and the methods used to evaluate them. To this end, they constructed a dataset of simple phrases that were especially designed to highlight how minor changes in sentences or phrases (e.g. small shifts in word order) could lead to major changes in human similarity judgements. In creating this dataset, they considered two types of compositional phenomena: i) adjective-noun composition and ii) the composition of a preposition and two noun phrases. The subjects in their study were shown a ‘base phrase’ (e.g. “A young woman in front of an old man”) from a list of 30 base phrases, and then for, each base phrase, four additional transformations:
a) Noun change (N): "A young man in front of an old woman."
b) Adjective change (A): "An old woman in front of a young man."
c) Preposition change (P): "A young woman behind an old man."
d) Meaning preservation (M): "An old man behind a young woman."
They find that humans demonstrate a systematic pattern in their similarity rankings (the meaning-preserving transformation is judged most similar, followed by preposition change, adjective change, and finally noun change), and that the best compositional semantic models of the time all fail to capture this pattern. Perhaps today’s models can do better?
Following the rapid rise of word2vec, Le and Mikolov (2014) extend Mikolov’s earlier work with word embeddings to arbitrarily long spans of text (“paragraphs”). Their approach relies on a concatenation of paragraph vectors learned in two different manners: i) by mapping every paragraph to a fixed-length vector and every word to an independent fixed-length vector - these mappings are then added or concatenated, and ultimately used to predict words in a sliding window; and ii) by using just the paragraph vector to predict words sampled from a random text window.
Kiros et al. (2015) present a seminal approach to unsupervised (albeit structured) sentence representation learning in Skip-Thought Vectors. The idea is as ingenious as it is simple: they use an encoder-decoder architecture to attempt to predict, given a sentence, the next and previous sentences. The encoder and decoder, inspired by similar architectures in neural machine translation, use an RNN (specifically, a GRU) to represent the sentence, with the encoder’s final hidden state being used by the decoder to reconstruct neighbouring sentences.

The name is a nod to the word-vector training skipgram algorithm – where, instead of functioning on an n-gram level, the system functions on a sentential level – a thought level, as it were.
Wieting, et. al (2015) offer a supervised approach (deemed Paragram), where representations are trained on phrase pairs from paraphrase data (PPDB). The try to force the representations of both phrases to be as close to each other as possible, and evaluate a variety of different encoders. To their surprise (and to everyone without a GPU’s relief), their simplest model – the average of word embeddings in a phrase – works much better than the more complicated models that involve, for instance, variants of recurrent networks. The authors revisit this work in 2016, where they employ character representations for composing sentences. In their experiments, this approach fares even better.
III. Recent approaches
Recent research in sentence representation learning can largely be characterized by a focus on transfer learning - that is, appropriating representations learned for a specific task (or multiple tasks) for use in another. Within this scope, it is possible to further categorize the majority of current approaches as belonging to one of two categories: supervised and unsupervised learning. The distinction between the two is one that pervades all of machine learning - namely, that supervised approaches involve labeled data, while unsupervised approaches are concerned with data that is unstructured or for which no labels are available. In the context of sentence representations, the former often refers to training a model for a specific task (or a suite of tasks) with the express goal of learning general-purpose representations that can be successfully transferred to other tasks. The latter, on the other hand, often involves extracting latent linguistic features from massive unlabeled corpora (usually in the context of language modeling) and representing unseen sentences via such features.
Supervised methods
The biggest question in recent work on supervised sentence representation learning has been that of the training task. In other words - what sort of objective would a model need to be trained towards in order to yield the best, general-purpose representations that are transferable? In most cases, this process involves training an encoder that learns to represent sentences for the task-at-hand via fixed-length dense vectors. Such an encoder can then encode unseen sentences for input to another task, where such representations might be useful.
Conneau et al. (2017)
Conneau et al. (2017)’s popular InferSent model imagines Natural Language Inference (NLI) to be an appropriate task for learning transferable sentence representations. In simple terms, given premise and hypothesis sentences, NLI is the task of classifying the relation of the hypothesis to the premise by describing whether it entails the premise, contradicts it, or does absolutely nothing relevant to it. NLI is often discussed as a sophisticated natural language understanding task, requiring a conception of reasoning and syntactic structure, which makes it an obvious candidate for sentence representation. The authors experiment with several architectures to this end – BiLSTMs with pooling, self-attentive networks and hierarchical ConvNets. They encode both premises and hypotheses with these encoders, creating output vectors that they plug into a classifier for the NLI task. In their experiments, they find that the BiLSTM with max-pooling is not only the best encoder for NLI, but is also the one that yields the best transfer performance.
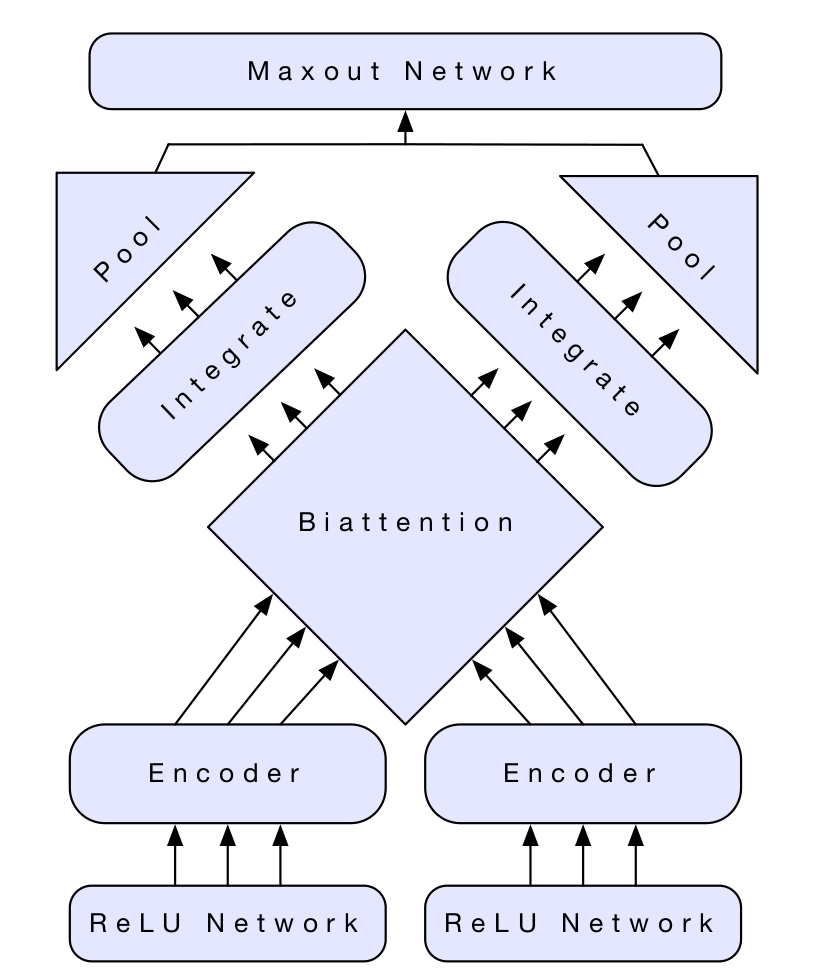
McCann et al. (2017)
McCann et al. (2017) rely on a very different task for sentence representation: neural machine translation. Specifically, they employ MT systems to train encoders, which they then include as part of a pipeline. They combine these sentence-sensitive word representations (called CoVe) in a network that incorporates bi-attention for obtaining sentence representations relevant to the downstream tasks. Essentially, rather than deriving fixed sentence representations from training on MT data, they continue to backpropagate through the sentence representations during transfer, working in attention between the two sentences. This is contrasted to how many other models would freeze the sentence representations during transfer, preferring instead to fine-tune the parameters of, for instance, a classifier subnetwork.
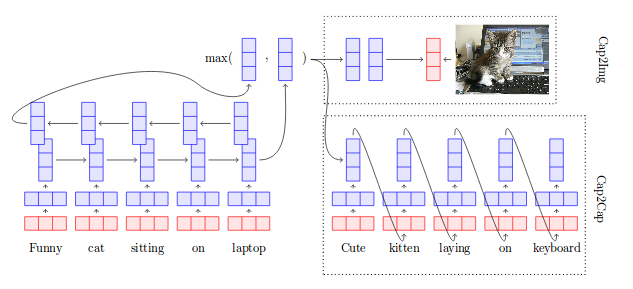
Kiela et al. (2017)
Kiela et al. (2017) experiment with grounding sentence representations by learning to predict visual content. Their intuition in doing so is that process of grounding will produce a “mental picture” of sentences, thereby enhancing the overall representation with another modality. Their approach is fairly straightforward – they employ the Microsoft COCO dataset, which contains images and multiple (up to 5) captions per image, and evaluate three models on it. The first uses a series of projections to map image caption representations (processed via BiLSTM) into the latent space of image representations (extracted from the final layer of a pretrained ResNet). The second ignores the images, and attempts to minimise the distance between the (multiple) captions per image. The third simply combines the two approaches. They also augment their models with embeddings learned without supervision (SkipThought vectors), under the intuition that just COCO by itself would only enhance representations of concrete objects, and not of abstract ones.
Subramanian et al. (2018)
Subramanian et al. (2018) experiment with consolidating a variety of tasks within a multi-task framework. They posit that doing so will combine the inductive biases of various training objectives in a single model. Intuitively, this would mean that the sentence representations produced in this fashion would be highly generalizable and could be transferred to various other tasks and domains. The tasks they settle on include previous and next sentence prediction (i.e. Skip-Thought), neural machine translation (En-De and En-Fr), constituency parsing, and natural language inference (AllNLI). Under this multi-task scheme, they are able to expand their training set to 124 million sentence pairs, which proves to be much larger than any of the methods mentioned earlier. They perform an ablation study of sorts, too, experimenting with different subsets of their tasks.
Most of the supervised tasks we’ve described here involve supervised training on corpora that are often distinct from the downstream task on which they’re evaluated. However, there remain several approaches to sentence representation learning that do not involve any sort of transfer learning. These attempt to condense sentence meaning specifically during the relevant task, which, in effect, is slightly similar to the use of the final state of a recurrent network.
Zhang et al. (2018)
Zhang et al. (2018) introduce “sentence-state” LSTMs (S-LSTMs), which extend the LSTM by representing every time-step with word-states for all words in that sentence, along with an independent sentence state. Updates are then based on weighted combinations of trigram word-states at the previous time-step, the previous sentence state, and the current input. The intuition here is that updates can infer how the previous word sees itself and its neighbours, how the previous word sees the whole sentence, as well the current input. This is contrasted with how the standard forward-LSTM only considers how the previous state sees what precedes it, and its own input. Although the the S-LSTM outperforms the(forward and bidirectional) LSTM on a variety of experiments, it is unfortunately not evaluated under any transfer scenarios.
Lin et al. (2017)
In this work, Lin et al. (2017) combine a standard LSTM with multi-headed self-attention, as introduced in the now-famous Attention Is All You Need. In general, this process first employs a simple linear combination on the hidden states of a bidirectional LSTM to generate multiple “mixes” along a particular hidden representation axis, which are then linearly re-combined after passing through a softmax normaliser. This is repeated multiple times to obtain multiple heads; the sentence representation is, therefore, a matrix and not a vector. The authors hypothesise that the use of attention takes some of the long-term memorisation load off the LSTM, as attention results in quick, simultaneous access to all timesteps.
Unsupervised methods
While the aforementioned methods leverage existing, annotated datasets for learning sentence representations, there remains a large body of work that takes unannotated data into account. There is a clear tradeoff here: while supervision from a given task (or tasks) can “steer” a network towards producing transferable representations as a byproduct, this approach is nonetheless limited by the amount of training samples available for the task in question. Unlabeled data, however, has the benefit of being orders of magnitude larger than labeled data - at the obvious expense of linguistic annotation. Methods utilizing the latter are often referred to as “unsupervised”, though this distinction is a contentious one. Some of these approaches motivated by a language modeling objective (i.e. given a sequence of words, predicting the following word), under the intuition that language modeling captures latent linguistic information that, in itself, is inherently transferable. Others involve principled ways of combining the pre-trained word embeddings that constitute sentence units - via averaging, for example. Note that sometimes, unsupervised methods may require logically sequential sentences, which makes them “structured” methods, as opposed to unstructured ones, that can deal with corpora of random sentences.
Radford et al. (2017)
One language modeling-based approach involves the use of the ByteLSTM (Radford et al. (2017)). Though the concept is fairly simple - they use character-level LSTMs to model sentences - what makes this paper particularly interesting is their focus on domains. They break from tradition (all two years of it, anyway) and employ the Amazon product reviews corpus as their training data instead of considerably larger-sized corpus like Wikipedia. The rationale here is that doing so will yield a high-quality representation of sentiment as a “proxy” of meaning. Their results confirm the usefulness of domain, as they obtain massive improvements on movie and product reviews. Results on other classification datasets are not particularly brilliant, however.
Cer et al. (2018)
Cer et al. (2018) introduce the Universal Sentence Encoder, which is a very pragmatic, user-oriented release. The system (implemented in TensorFlow) includes two encoders – the first is a transformer, (i.e. the encoder bit from Attention Is All You Need), and the second is a ‘deep averaging network’, which, inspired by Iyyer et al., uses a deep network to simulate something akin to an average over the word representations in a sentence. The idea builds on the fact that merely averaging word vectors to represent a sentence adequately capture minor lexical differences that result in major semantic differences. For instance, swapping a word out with its antonym in a very long sentence would fundamentally change the meaning, whilst having both averages be very close to each other. The authors attempt to solve this problem by adding dense transformation layers to vector averages, hoping that this would help them capture these minor differences better. Both networks are also augmented with supervised training, making this paper fit into both this section and the previous one.
Hill et al. (2016)
Hill et al. (2016)’s work is an unsupervised counterpart to Hill et al. (2015)’s work on embedding dictionaries. Here, the authors propose two architectures. The first of these is the sequential denoising autoencoder (SDAE), which adapts the denoising autoencoder often employed for image processing to a text domain. They induce ‘noise’ in a sentence via a noise function, which deletes each word $w$ with some probability \(p_0\), and scrambles each non-overlapping bigram \(w_iw_{i+1}\) with some probability \(p_x\). They then use NMT-esque encoder-decoder architectures to learn to denoisify the scrambled sentence. This method has the added advantage of not requiring structured unlabelled data: sentence contexts are not taken into account.
Another architecture Hill et al. (2016) propose is deemed FastSent, which is a simplified, faster variant of SkipThought. Here, rather than relying on a sequential encoder, they simply sum up the embeddings in the source sentence. The network then attempts to predict every word in the target sentence given this sum. They also add a variant that forces the summed source sentence vector to predict its own words. Overall, these architectures prove to be much faster to train than SkipThought, while yielding comparable quality representations.
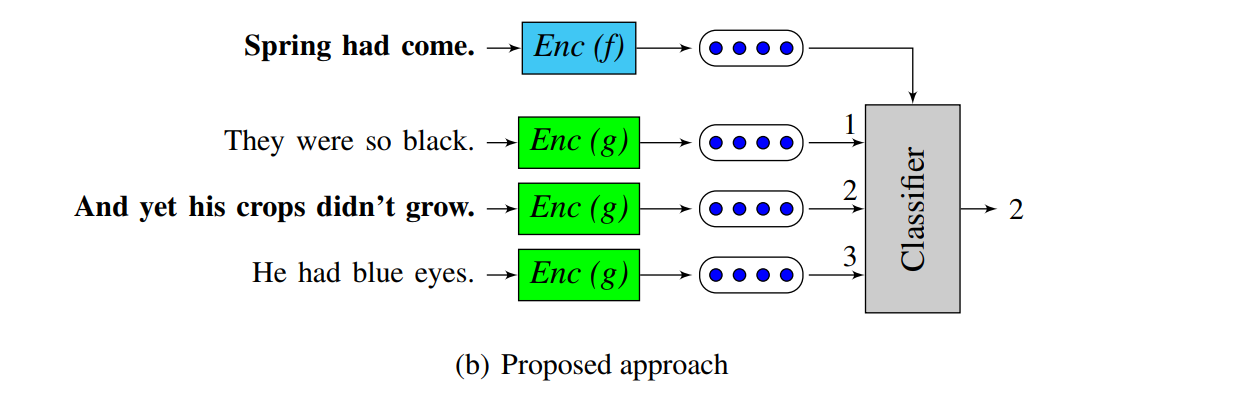
Logeswaran and Lee (2018)
Logeswaran and Lee (2018) offer another, efficient framework for learning sentence representations that relies on simplifying the SkipThought architecture. Here, they swap out the reconstruction style target-sentence-building of Skip-Thoughts with multiple choices. Essentially, given a sentence and a set of candidate following sentences, the model learns to predict the best candidate in the latter. The intuition here is that such a process can steer the network towards learning some semblance of meaning instead of simple word surface forms.
Tang and de Sa (2018)
Tang and de Sa (2018) demonstrate how to exploit invertible decoders, also in the context of the SkipThought framework. Here, they propose an encoder-decoder system that attempts to maximise the averaged log-likelihood for every word in the target sentence, given the representation for that word, as well as the decoded last GRU hidden state for the source sentence. The catch is that their decoders are all invertible mathematical functions. The first of these is a linear projection \(f_{dec}(\mathbf{z}) = \mathbf{Wz}\), that, when inverted, yields \(f_{dec}^{-1}(\mathbf{x}) = \mathbf{W}^\top(\mathbf{WW}^\top)^{-1}\mathbf{x}\). The second decoder is a bijective function that creates a one-to-one mapping between the GRU hidden state and word representations. This means that the two have to be exactly the same size, which is achieved by adding a linear transformation to normalise sizes. The test phase then involves merely inverting the decoder and employing it to obtain sentence representations.
Arora et al. (2017)
Arora et al. (2017) present a “simple but tough to beat baseline” for building sentence representations from word vectors. Their method is “embarrassingly simple”, requiring no training and delivering results which are comparable to fully supervised methods. They compute the weighted average of the word vectors in the sentence and then remove the projections of the average vectors on their first principal component (“common component removal”). The weights are assigned to words based on their frequency, using the following term: \(\dfrac{a}{a + p(w)}\) with \(a\) being a hyper-parameter and \(p(w)\) being the (estimated) word frequency. They call this the “smooth inverse frequency”. It’s a term which is very similar to TF-IDF, but which they empirically show leads to better performance in this setting. The paper includes a neat analysis of denoising the embeddings by subtracting the projection of the first principal component leads to better sentence representations (the first principal component contains noise which is “common” and so is not semantically relevant).
Yang et al. (2018)
Similar to Arora et al. (2017)’s approach, Yang et al.’s work involves no training of its own, and instead relies on effectively combining pre-trained word embeddings. Generally, their method relies on the Gram-Schmidt process, which, given a set of vectors representing words in a sentence seen thus far, creates an orthogonal basis that represents the same subspace as the original. The addition of a new word to the sentence can be expressed as a linear combination of the pre-existing basis, plus an additional orthogonal component representing the new word, weighted by some scalar. The authors hypothesise that first of these terms represents pre-existing semantic meaning (already found within the vector space), while the second is the novel contribution of the new word. As a result, their relative magnitudes create a novelty score for the vector in context, which is then added to a calculated significance score and a corpus-wise uniqueness score. Word vectors in a sentence are ultimately weighted by their respective scores and added to obtain a sentence representation.
IV. Method comparison
In this section, we will attempt to contextualize the aforementioned sentence representation approaches as they relate to a variety of transfer tasks. First, however, it is important to note that not all papers involve transfer learning – several are evaluated on the same tasks they were trained on, making direct comparisons with transfer-based methods slightly unfair. Also, some of the systems we have reviewed employ different corpora - particularly the “unsupervised” approaches. While one could say that this should not affect a comparison of results, this factor nonetheless shifts the evaluation from being an evaluation of the conceptual performance of encoders to being an evaluation of their performance, conditioned by their environments (including domains, corpora sizes, etc.). Finally, it must be noted that not all authors necessarily attempted to beat state-of-the-art in their experiments. For instance, Radford et al. (2017)’s byteLSTM was intentionally designed to evaluate the impact of training domain, and Kiela et al. (2017) state that they intended to measure the impact of adding image data more than they did actual performance.
Results
Since most of the methods we have mentioned so far precede any proposed sentence representation evaluation framework, they are evaluated across a variety of different downstream tasks. Fortunately, the overlap between these tasks is large enough between papers that we can consolidate the reported results into one table. We thus report results on the following tasks:
- A set of classification tasks, including MR and SST (movie reviews), CR (product reviews), SUBJ (subjectivity/objectivity), MPQA (opinion polarity), TREC (question type classification).
- A variety of Natural Language Inference (NLI) datasets, that involve specifying whether one of two statements entails the other: specifically, the SNLI and SICK-E corpora.
- Semantic relatedness tasks, that involve ranking the semantic similarity between two sentences: the STS and SICK-R corpora.
- Paraphrase identification, which involves identifying whether one of two sentences is a paraphrase of the other: this uses the MSRP dataset, also referred to as MRPC in some papers.
- COCO, a dataset of images and corresponding captions; the relevant downstream task involves ranking captions by their relevance to given images, or vice versa.
A further caveat here is that virtually all the papers we have reviewed evaluated multiple configurations, which differed either in structure or in hyperparameter choice. Providing exhaustive results for all these variations would make this section largely unreadable, and we therefore pick the “best” systems from each paper, described when you hover over the names. Our table is arranged into three sections: supervised transfer methods, unsupervised transfer methods, and supervised task-specific methods.
| Paper | Trained on | MR | CR | SUBJ | MPQA | TREC-6 | SST-2 | MSRP | SNLI | SICK-E | SICK-R |
|---|---|---|---|---|---|---|---|---|---|---|---|
| InferSent, BiLSTM-Max | AllNLI | 81.1 | 86.3 | 92.4 | 90.2 | 88.2 | 84.6 | 76.2/83.1 | 84.5 | 86.3 | 0.884 |
| Char+CoVe-L | en-de, WMT 2017 | 95.8 | 90.3 | 88.1 | |||||||
| Cap2Both | COCO | 79.6 | 81.7 | 93.4 | 89.4 | 84.8 | 72.7/82.5 | 76.1 | 81.6 | ||
|
MTL, +STN+Fr+De+NLI+2L+STP
|
Multiple | 82.8 | 88.3 | 94.0 | 91.3 | 92.6 | 83.6 | 77.4/83.3 | 87.6 | 0.884 | |
| Paragram | PPDB (XL) | 79.7 | 84.94 | 0.831 | |||||||
| MC-QT | BookCorpus | 80.4 | 85.2 | 93.9 | 89.4 | 92.8 | 76.9/84.0 | 0.868 | |||
| SDAE | BookCorpus | 74.6 | 78 | 90.8 | 86.9 | 73.7/80.7 | 0.46* | ||||
| FastSent | BookCorpus | 70.8 | 78.4 | 88.7 | 80.6 | 72.2/80.3 | 0.72* | ||||
| SkipThought | BookCorpus | 76.5 | 80.1 | 93.6 | 87.1 | 92.2? | 73.0/82.0 | 0.858 | |||
|
Hierarchical+Composite-emb
|
BookCorpus | 77.77 | 82.05 | 93.63 | 89.36 | 92.6 | 76.45/83.76 | 0.861 | |||
|
Invertible linear projection
|
BookCorpus | 81.3 | 83.5 | 94.6 | 89.5 | 90 | 85.9 | 76.5/83.7 | 85.2 | 88.1 | |
| byteLSTM | Amazon reviews | 86.9 | 91.4 | 94.6 | 88.5 | 75.0/82.8 | 0.792 | ||||
| Deep averaging network |
Multiple
|
74.45 | 80.97 | 92.65 | 85.38 | 91.19 | 77.62 | ||||
| Transformer | Multiple | 81.44 | 87.43 | 93.87 | 86.98 | 92.51 | 85.38 | ||||
| GEM (+ LFP) | -- | 79.8 | 82.5 | 93.8 | 89.9 | 91.4 | 84.7 | 75.4/82.9 | 86.2 | 86.5 | |
| sLSTM | 82.45 | ||||||||||
|
Structured self-attention
|
84.4 | ||||||||||
|
Dynamic self-attention
|
88.5 | 87.4 |
V. On evaluation
Our method comparison section should have demonstrated how difficult the prospect of evaluation can be. In fact, the topic of evaluating the quality of vector-based representations of language is perhaps as old as the topic of vector-based representation of language itself. In the context of word-level representations, evaluation methods have historically been split into two different categories: intrinsic and extrinsic. The former largely relates to measuring the extent to which information encoded in word-level vectors aligns with human intuitions about language. As such, intrinsic approaches may include tasks like measuring the correlation the cosine difference of two word vectors and the Likert-rated human similarity judgment for the same words (see here), or answering analogy questions. Extrinsic methods, on the other hand, are largely concerned with assessing the utility of different vector-space models in downstream tasks, such as Part-of-speech Tagging or Named Entity Recognition. Though each evaluation methodology has its own inherent trade-offs in isolation, evaluating word-level vector-space models via a combination of both intrinsic and extrinsic approaches has often provided a fairly good indication of the inherent quality of a given vector-space model.
At the sentence-level, evaluation becomes significantly more difficult. This is due largely in part to the complexity of sentences as units of language compared to words. One can imagine that, while words may carry a number of discrete linguistic features (e.g. part-of-speech, tense, number, etc.) and, perhaps, some latent features regarding sense, a sentence must account for all of these per its constituent words, as well as higher-order information relating to semantics, pragmatics, etc. As a result, it becomes difficult for researchers to reach a consensus in regards to precisely what information should be assumed to be encoded within a sample sentence representation. Related to this, the distinction between intrinsic and extrinsic evaluation becomes increasingly blurred in the context of sentences. For example, while the task of measuring vector similarity at the word level arguably offers little utility outside of verifying human linguistic intuitions, doing so at the sentence level has clear practical applications in information retrieval (in addition to yielding linguistic insights). For these reasons, evaluation of sentence representations has largely leaned towards measuring performance of vectors as input in various downstream transfer tasks. Some recent work, however, has approached evaluation in a more systematic fashion. We will review a small sample of these efforts below.
Conneau and Kiela (2018)
Conneau and Kiela (2018) present SentEval: a toolkit focused on the evaluation of vector-based sentence representations in various transfer settings. Fundamentally, the toolkit is a collection of tasks, selected based on “what appears to be the community consensus”. It includes several preprocessing scripts, as well as a set of both supervised and unsupervised downstream tasks. The former rely on fixing the sentence representations obtained prior to transfer and training the parameters of task-specific classifiers, while the latter employ similarity metrics and other similar measures. With this in mind, SentEval attempts to bring a sense of ease to representation evaluation, in addition to a degree of standardization. In their sample evaluation, the authors note that the non-transfer encoders, which train representations on specific tasks, perform better than transfer-based methods, noting that overcoming this discrepancy is a vital direction for the future of representation learning.
Conneau et al. (2018)
Conneau et al. (2018) offer an evaluation approach that is similar in spirit to SentEval, but very distinct in its methodology. They introduce a set of sentence probing tasks that, instead of measuring downstream performance of representations on concrete tasks, attempt to evaluate exactly what sort of information vectors can store about the sentence they encode. In a sense, they involve querying (“probing”) a vector for properties that should be obvious given the original sentence. In total, Conneau, et. al probe for a total of ten phenomena over three categories: surface-level (eg. sentence length), syntax-level (eg. parse tree depth) and semantic-level (eg. tense). The authors also correlate performance on these probing tasks to downstream performance on SentEval tasks. Here, they find that surface-level phenomena are significantly more strongly correlated than syntactic or semantic phenomena.
Wang et al. (2018)
The GLUE benchmark proposed by Wang et al. (2018) is a collection of natural language tasks specifically geared towards natural language understanding (NLU). The tasks included therein are intended to assess the ability of machine learning systems to generalize across a variety of complex NLP tasks including NLI, paraphrase detection, sentence similarity, among others. Outside of task selection, the primary difference between GLUE and SentEval is that GLUE, as a framework, does not evaluate just sentence representations in isolation, but entire systems. It therefore allows (encourages, even) the use of interaction (eg. soft attention) between input sentence pairs.
McCann et al. (2018)
The Natural Language Decathlon (decaNLP) proposed by McCann et al. (2018) is benchmark that similar in spirit to GLUE, comprising ten total NLP tasks. Though it does not focus specifically on NLU like GLUE, decaNLP nonetheless demands that participating models can effectively generalize across a wide array of tasks, such as question answering, machine translation, summarization, semantic parsing, among others.
Closing remarks
In this post, we intended to provide a comprehensive summary of past and current methods in sentence representation learning for NLP. However, you may have noticed one glaring omission in our survey thus far: language-modeling based contextualised word-representation approaches like ELMo, ULMFiT, and BERT. These methods can be understood as a replacement of the vectorial representation with a matrix representation where each word’s representation includes information about its context. In the next post, we will turn our attention to what happens on sesame street.